|
|
《一种简单有效、即插即用的探索样本关系通用模块》
论文题目:BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
论文地址:https://arxiv.org/pdf/2203.01522.pdf
论文代码:https://github.com/zhihou7/BatchFormer 一、研究背景
尽管如今的深度神经网络已经取得了巨大的成功,但是它严重依赖于大量的数据,仍然面临着来自于数据稀缺的各种挑战,比如数据不平衡,零样本分布,域适应等等。前人的研究未能探索深度神经网络的内在结构 for 学习样本关系(没有去挖掘内在的网络结构来使网络模型建模关系)。
如何在稀缺数据的场景(长尾学习,少样本学习,零样本学习,领域泛化)下提高泛化能力?
可以利用不同样本的相似性、共享的part和Transferable augmentation(e.g., angles)
"Transferable augmentation" refers to a type of data augmentation that can be transferred between different tasks or datasets in deep learning.In this context, "angles" could refer to the rotation of images or other data points in a dataset during training to improve model performance.
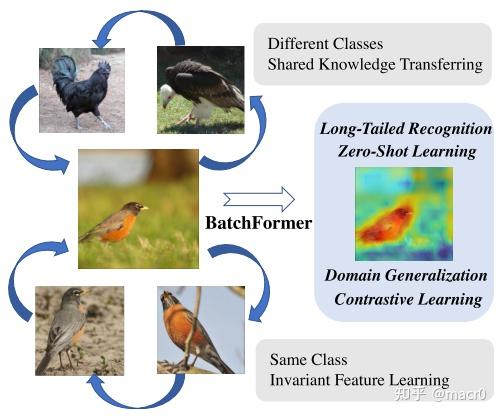
公鸡、知更鸟、秃鹫共享体形和爪形
在最近的数据稀缺性研究方法中,通过约束(文中是regularization)和知识迁移对样本关系进行了深入探索,简单且有效的方法是从现有的训练数据直接生成新的数据样本/域。
- 样本间存在相似关系和共享部分的关系来增强数据约束模型:mixup,copy-paste,crossgrad和组合学习。
- 知识迁移:1. 在频繁类别和稀有类别之间;2. 从已见类别到未见;3. 已知域和未知域
本文主要贡献:1. 提出从深度神经网络内部结构的角度探索样本关系; 2. 设计了BatchFormer,即插即用,用于探索每个小批处理中的样本关系; 3. 证明了BatchFormer在各种视觉识别任务中的有效性。
Abstract和Introduction 可以去作者知乎文章看,有很详细的介绍。BatchFormer: 一种简单有效、即插即用的探索样本关系通用模块 (CVPR2022) - 知乎 (zhihu.com) 二、研究内容
以下引用为原文:
受这些启发,作者提出了一个使网络能够从训练批次(min-batch)中学习样本关系的简单有效并且即插即用Transformer模块,Batch TransFormer (BatchFormer)。BatchFormer应用于每个训练批次数据的batch维度来隐式地探索样本关系。BatchFormer使每个批量的样本间能够互相促进学习,比方说,在长尾识别中,利用频繁类别数据促进稀有类别的样本的学习。更进一步地,由于在训练的时候在batch维度引用了Transformer,训练和测试的数据分布不再一致了。因此我们提出一种共享分类器的策略,来消除在训练和测试的分布偏差从而达到Batch不变学习,进而使我们在测试的时候能够移除BatchFormer。这种共享策略使BatchFormer在测试时不增加任何计算负载。不需要任何额外的策略,BatchFormer 在10多个数据集上面展示了稳定的提升,包括了长尾分布,组合零样本学习,领域泛化,领域适应,对比学习。最后但是更重要的,基于DETR,我们进一步将BatchFormer扩展到像素级别的任务上面,包括目标检测,全景分割,图像分类.改进版的BatchFormer能够即插即用于DETR, Deformable DETR, Conditional DETR, SMCA, DeiT. Overview
在现有的方法中,样本关系通常需要在一个明确的方案中定义,然后才能用于学习,从而不能自动学习样本关系用于表征学习。作者从学习的角度考虑样本关系,目标是使深度神经网络本身能够在端到端的深度表示学习中从每个小批量样本(mini-batch)中学习样本关系。如下图所示:
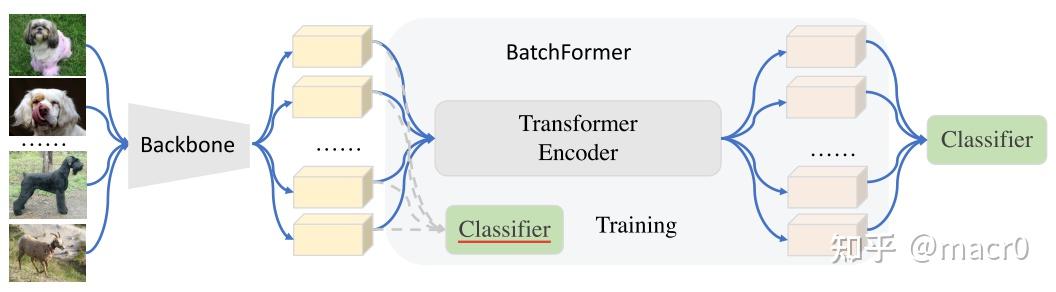
第一个是辅助分类器,第二个是最终分类器
Backbone首先用于学习单个数据样本的表示,不同样本之间没有交互(mini-batch)。 在此基础上,引入了一个新的模块,利用Transformer中的交叉注意机力机制来建模不同样本之间的关系,称之为BatchFormer模块。BatchFormer的输出随后被用作最终分类器(final classifier)的输入。
Transformer中的cross-attention mechanism是一种注意力机制,它将两个不同的嵌入序列混合在一起,这两个序列必须具有相同的维度 为了弥补训练和测试之间的差距,作者还在BatchFormer模块之前使用了一个辅助分类器(auxiliary classifier),即通过在最终分类器和辅助分类器之间共享权重,将从样本关系中学习到的知识传递给backbone和辅助分类器。因此,在测试(testing)时我们可以去掉BatchFormer,直接使用辅助分类器进行分类。
BatchFormer
Transformer Encoder:
Transformer Encoder由多头多头注意力机制(MSA)和MLP组成,LN层在每个块之后。 X\in R^{N\times C} 表示一个输入特征序列, N 为序列长度, C 为输入特征的维度, l 为Transformer Encoder中各层的 index 。则Transformer Encoder的输出为:
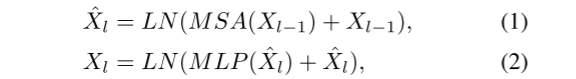
我们在特征提取器后面插入TransFormer模块。特别地,我们的Transformer是沿着batch dimension, 也就是说我们把整个batch看做一个sequence。再这里,我们移除了Transformer的positional embedding以达到位置的不变性学习。 MSA被广泛地用于以通道和空间维度来建模关系,所以作者认为MSA也可以扩展到处理batch维度的关系。因此,与传统的transformer layers不同的是BatchFormer的输入首先会被reshape \Rightarrow 使transformer layers可以在输入数据的batch维度上工作。这样,transformer layers中的MSA就变成了BatchFormer中不同样本之间的交叉注意力。
By doing this, the self-attention mechanism in transformer layers then becomes the cross-attention between different samples for BatchFormer Shared Classifier:
由于不能假设用于测试的batch数据(也就是说用于测试的数据未知),例如样本关系,在BatchFormer模块之前和之后的特征之间可能存在差距。 也就是不能通过直接去除批BatchFormer来对新样本进行推理(如果直接去除,而不加新模块,那就相当于原网络直接少了一个模块,直接去除后肯定效果不一样了,保持训练和测试的batch不变性)。因此作者引入了辅助分类器,它从最终分类器中学习,而且和BatchFormer之前的特征保持一致(因为它直接连接BatchFormer之前的模块)。通过这个“共享模块”在测试过程中就算删除了BatchFormer也仍然能从之前使用BatchFormer进行样本关系学习中受益。
辅助分类器和最终分类器共享参数和权重,但是辅助分类器还从backbone的输出进行学习。最终分类器学习BatchFormer的输出。 loss 是辅助分类器和最终分类器的总 loss ,一起算的,最后进行权重共享。

A Gradient View
为了更好地理解BatchFormer是如何通过探索样本关系来帮助表征学习的,作者还从梯度优化的传播角度给出了直观的解释。 没有BatchFormer,所有 loss 只在相应的样本和类别上传播梯度(即一对一),而使用了BatchFormer则对其他样本上也有梯度(虚线),如图下所示,给定样本 X(X=X_0,X_1,X_i,...,X_{N-1}) 和在mini-batch中相对应的 losses : L_0,L_1,L_i,...,L_{N-1}
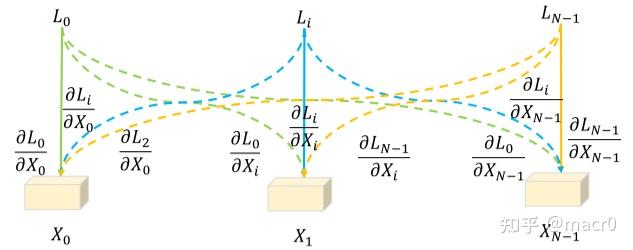
虚线表示样本件新的梯度传播
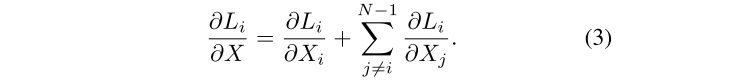
从上面这个公式我们可以看出,BatchFormer带来了新的梯度项 \frac{\partial L_i}{\partial X_j} (i\ne j) ,从梯度优化的角度来看 L_i 还根据样本 X_j 优化了网络。换句话说 X_j 可以看作是 y_i 的一个虚拟样本,其中 y_i 是 X_i 的标签。BatchFormer通过在mini-batch中的样本之间的关系建模,为每个标签 y_i 隐式地增加了 N-1 个虚拟样本。
virtual sample是指通过对原始数据进行一定的变换,如旋转、平移、缩放等,从而得到一些虚拟的样本,以增加训练数据的多样性,提高模型的泛化能力。 三、实验结果
1. 长尾识别Long-Tailed Recognition:
CIFAR-100-LT、ImageNet-LT、iNaturalist 2018、Places-L
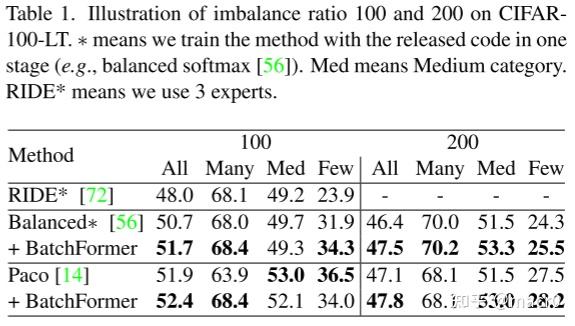
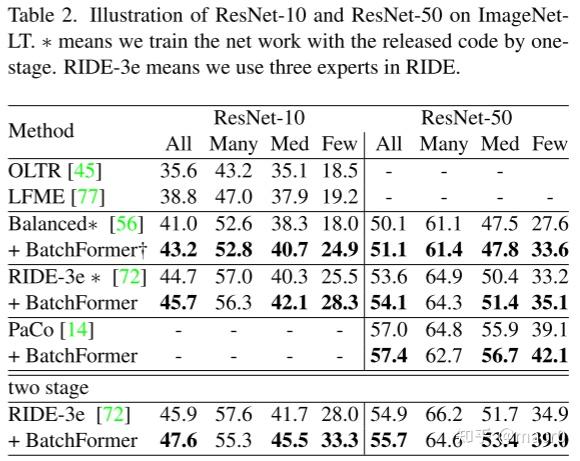
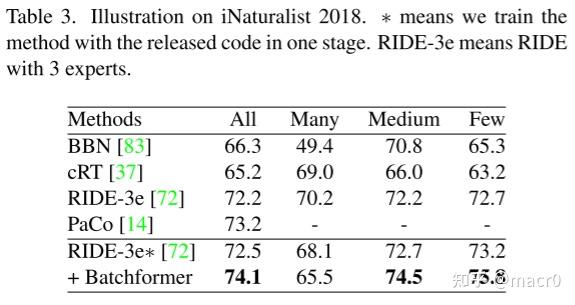
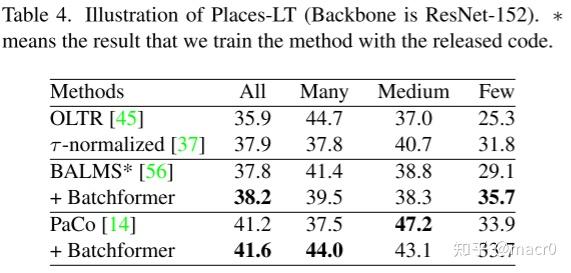
2. 零样本学习Zero-Shot Learning:
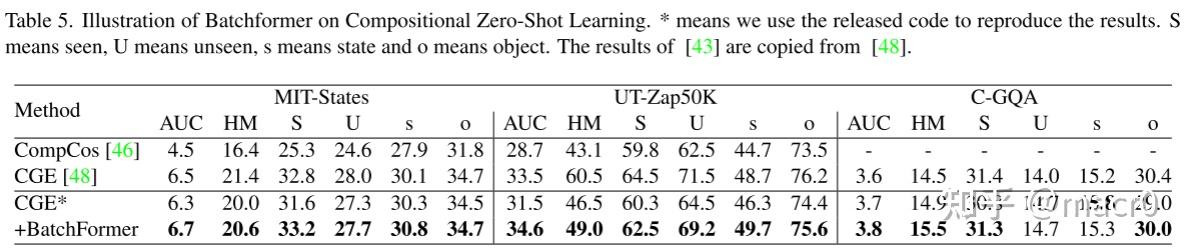
3. 领域泛化Domain Generalization:
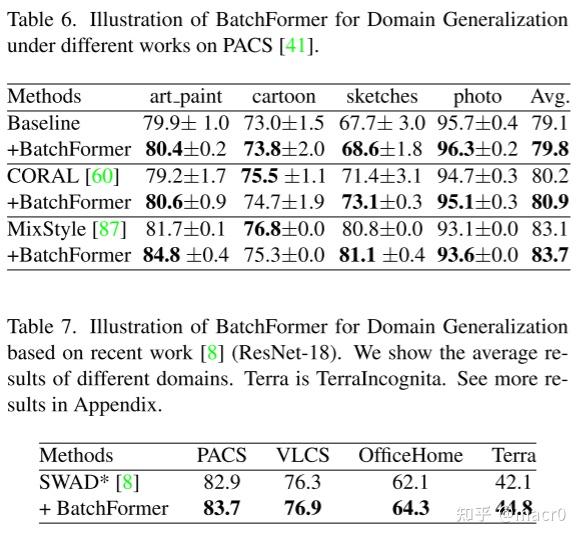
4. 自监督学习Self-Supervised Learning:

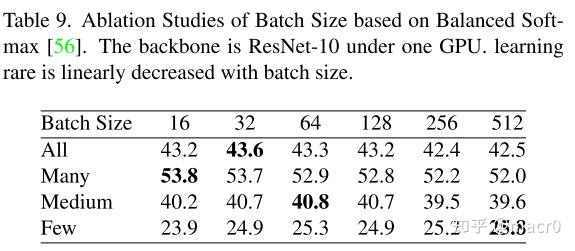
5. 消融实验:
batch size的大小,也表示transformer的size
是否使用共享分类器
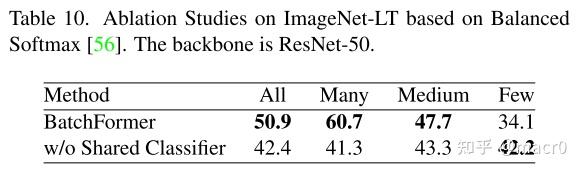
ImageNet-LT是一个数据集,ALL、Many、Medium、Few是指ImageNet-LT数据集中的图像数量。ALL表示所有的图像,Many表示图像数量大于100,Medium表示图像数量在20到100之间,Few表示图像数量小于20 6. 可视化分析:
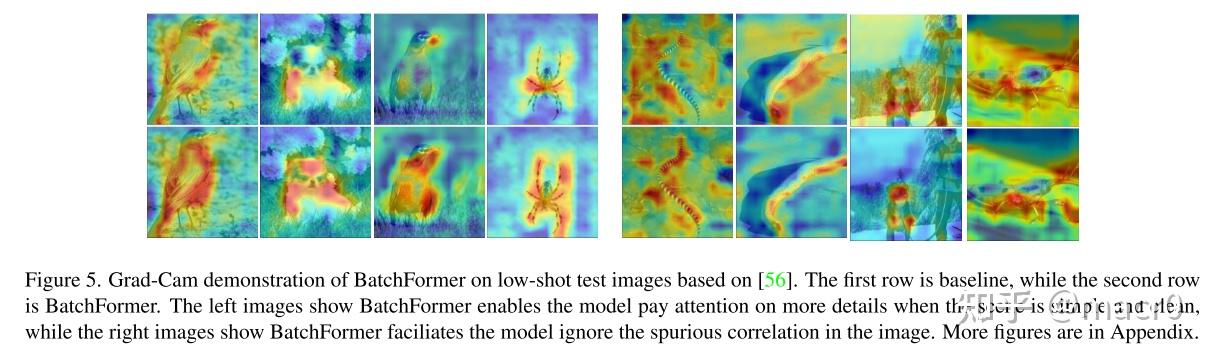
可视化比较:
BatchFormer关注对象的更多细节,忽略虚假的相关性。 1. 当图像包含干扰因素较多的复杂场景时,BatchFormer有效地提高了网络对相应目标区域的关注度(如图中沙滩上的海蛇、雪地上的狗和树叶上的昆虫)。 2. 当场景清晰时,BatchFormer会更多地关注对象的区域(如图中的鸟、狗和蜘蛛)。
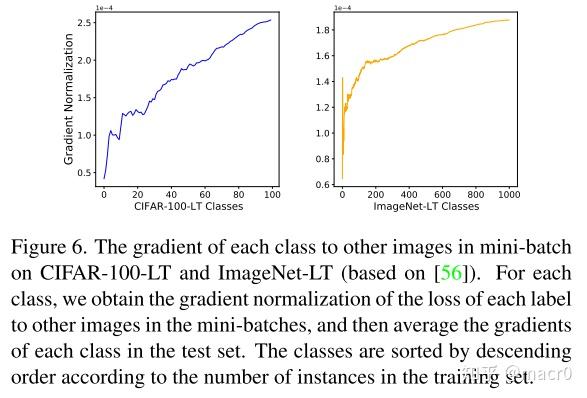
梯度分析:
BatchFormer增加了新的backforward梯度(increased new gradient backward):每个标签的 loss 在其他图像上都有梯度。换句话说,BatchFormer隐式地增加了mini-batch中每个图像类的样本。Mini-Batch中的其他图像也可以看作当前Image类的虚拟实例。梯度与每个图像标签对其他图像的effect紧密相关。下图说明了 class 越稀有,该 class 在mini-batch中的其他图像上的梯度就越大。因此,Batchformer实际上利用其他图像,通过增加其他图像上的few-shot标签的梯度来促进low-shot识别。
四、总结
提出BatchFormer,可以看作是虚拟样本增强,从而提高了表征学习。
Limitations:BatchFormer对strong data augmentation和balanced distribution的模型的改进是有限的。
BatchFormerV2:作者将BatchFormer泛化为了一个更通用的模块,来促进一般的计算机视觉任务,比如目标检测和分割,图像分类。https://arxiv.org/pdf/2204.01254.pdf
我在读的时候参考了以下博文:
BatchFormer: 一种简单有效、即插即用的探索样本关系通用模块 (CVPR2022) - 知乎 (zhihu.com)
《BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning》 - 知乎 (zhihu.com) |
|



 发表于 2023-4-19 16:03:32
发表于 2023-4-19 16:03:32